Introduction
Word Count: 192
Hello there, my name is Ethan! As of writing this, I am 20 years old and started my journey at Full Sail University in 2021.
My original degree path was the Game Development Computer Science program, but wanting to explore more opportunities in computer science led me to the Artificial Intelligence concentration.
I have always been involved with technology from a very young age. I first heard about Full Sail University in a game magazine when I was 10 years old. I ripped out the flyer and kept it as a reminder of what I wanted to do!
After going through the entire game development course and now the artificial intelligence course, I'm finally ready to finish off my bachelor's studies.
The purpose of these blogs is to document my progress during my four-month-long capstone project that I will be working on with a team.
My goal is to have an end product that I am proud of and that has some innovation built in. I don't want to have a generic project as my last one, but something exciting and new that will highlight my work here at Full Sail University.
Research and Planning
Word Count: 389
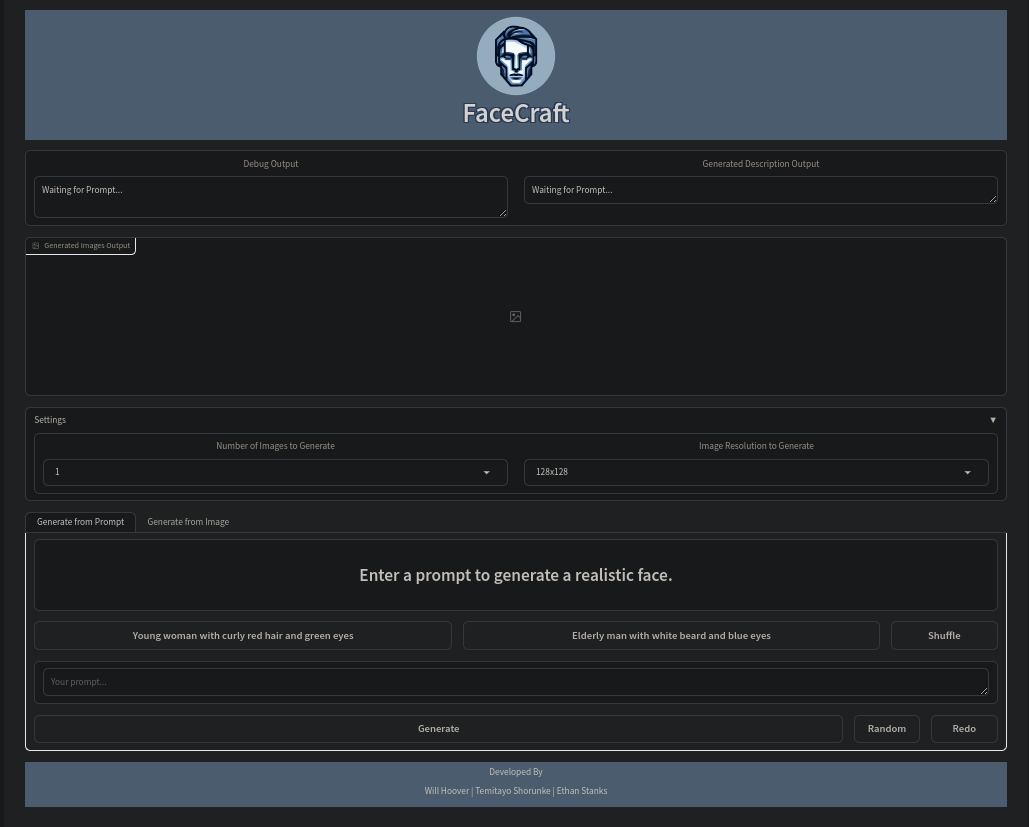
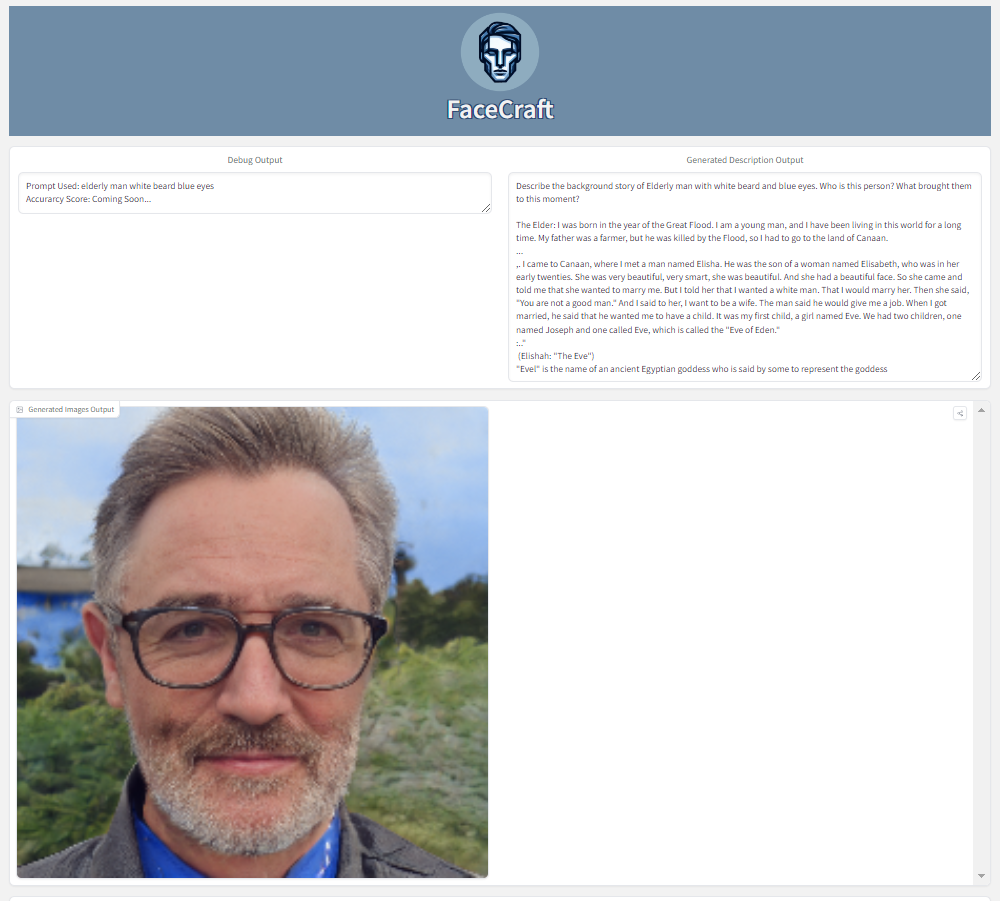
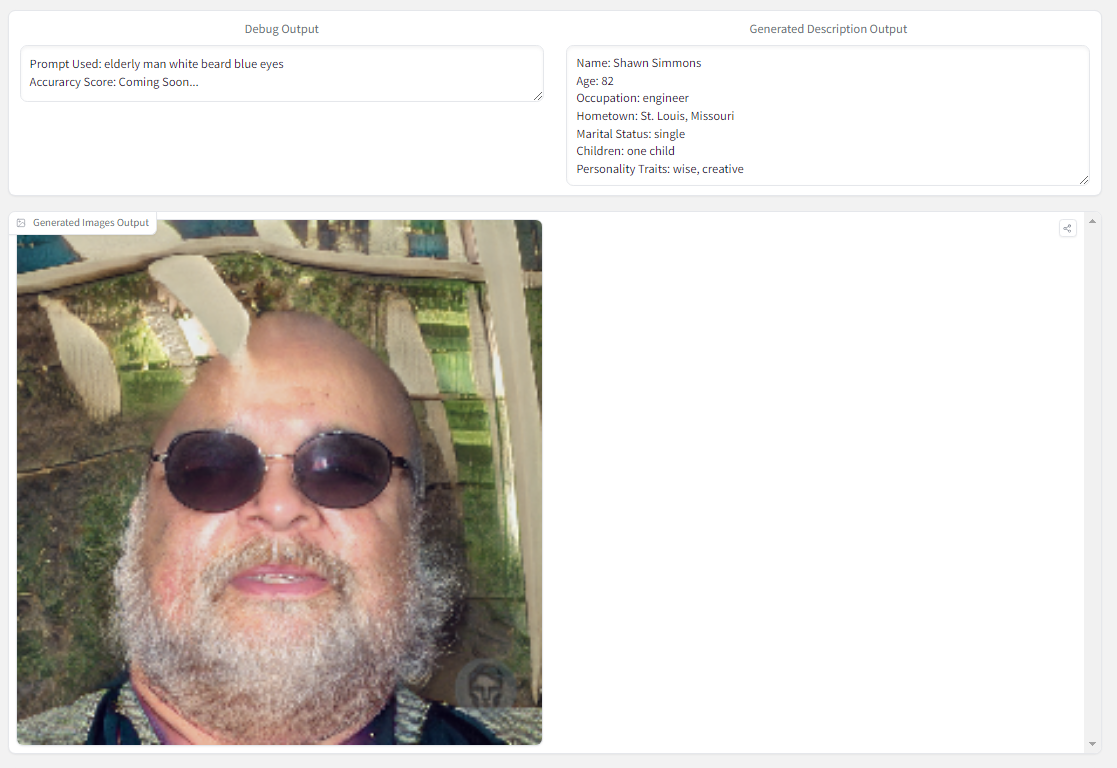
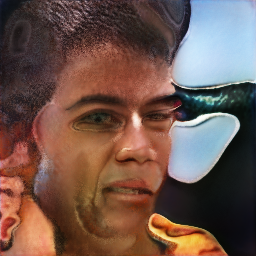
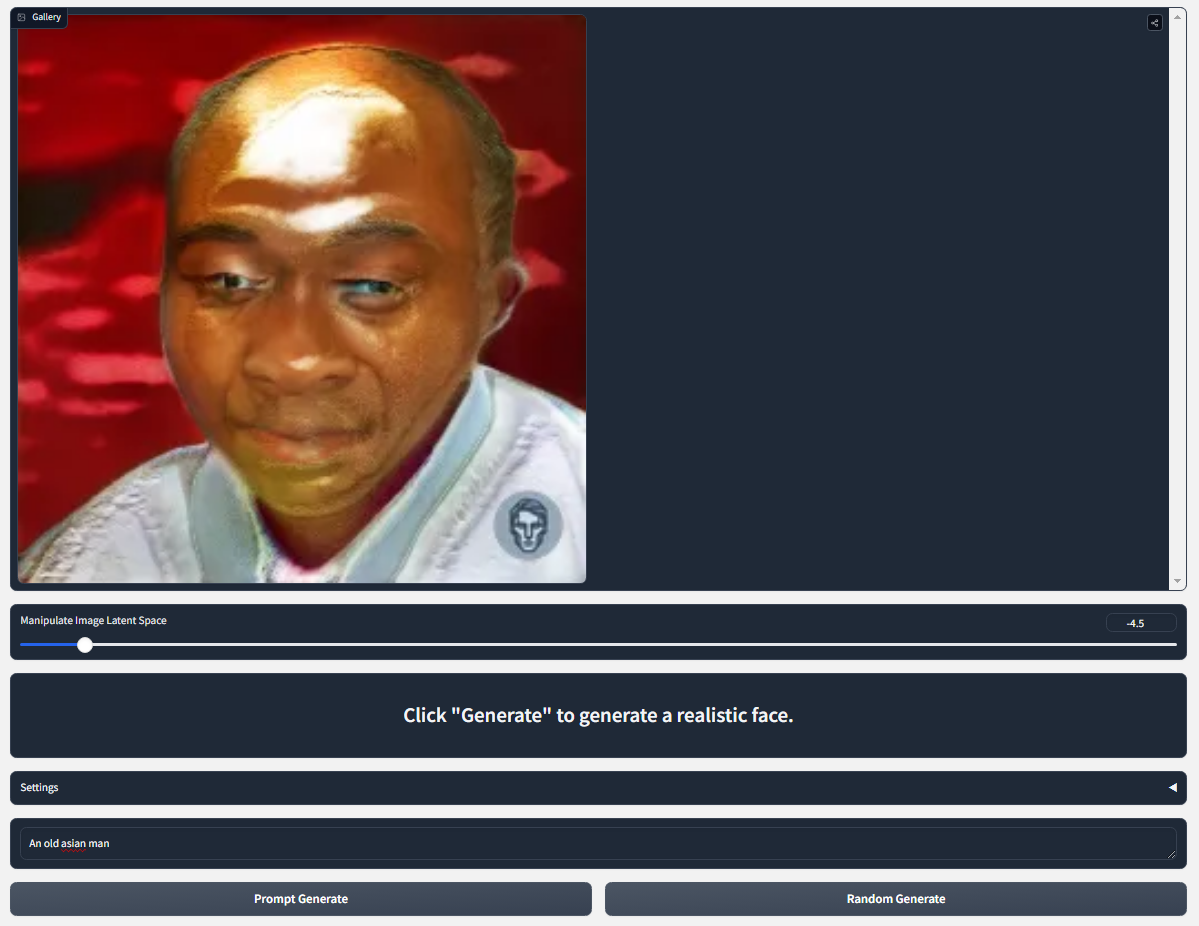
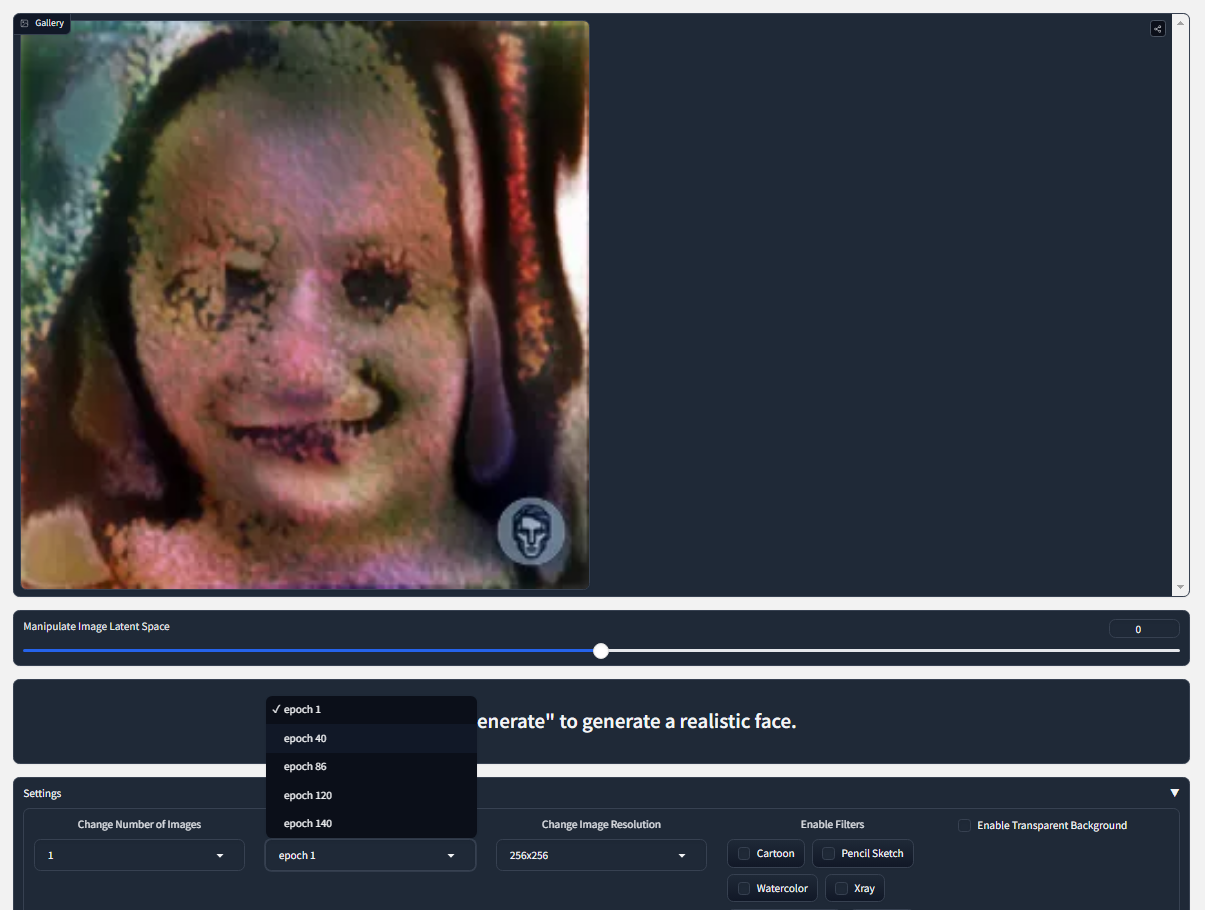
My team and I are currently wrapping up week two of our first month. Last week, we decided on a project idea out of the three of our pitches. Will's Pitch is an artificial intelligence anti-virus for detecting malicious threats in the firewall. Temitayo's pitch is a machine learning GANs model that generates realistic faces from prompts using NLP. My pitch is an Android app that uses machine learning to recommend recipes based on user feedback and the ingredients in their kitchen. We all agreed that Temitayo's realistic face GANs model would be a perfect project to finish off our degree and showcase our abilities.
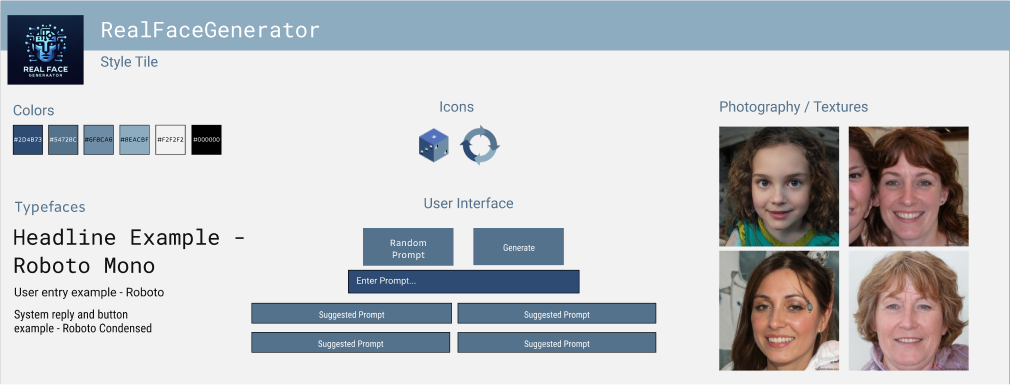
This week, the team and I got together to create the first draft for our project's design document and style tile. The style tile allows us to get the look and feel of our application without committing to it. The style tile includes the colors, typefaces, icons, user interface, and photography of how we plan on designing our wireframe for next week.
The design document went over our project's purpose, goals, requirements, development environments, use cases, and production plans. As of now, the model is set to be developed in PyTorch. Only Temitayo has experience in PyTorch, but Will and I wanted to be exposed to it as we only have experience in TensorFlow. The back-end will be developed with Django. The front-end will be developed with React. I have no experience with any of these tools, but a handyman shouldn't only know how to use a hammer but all the tools in his toolbox. With that being said, I told the team I'd like to take on the role of front-end with React.
The following days, after creating the first draft for the design document, I explored LinkedIn Learning to get a feel for React. I have completed two courses as of right now to get me ready for the first month of development next month. The first course covered the basics, like creating new components, setting up development tools in Chrome, using built-in hooks, and setting up test cases. The second course has me creating a React app from the ground up, using built-in hooks, and setting up more test cases. For the next two weeks of month one, I plan on continuing my research with React to further my front-end abilities.
Project Management
Word Count: 406
My team and I have one more week of planning until development starts. This week the team got together to complete the final draft of our design document, create the first draft for our front-end wireframe, and lastly, create our Jira board for project management.
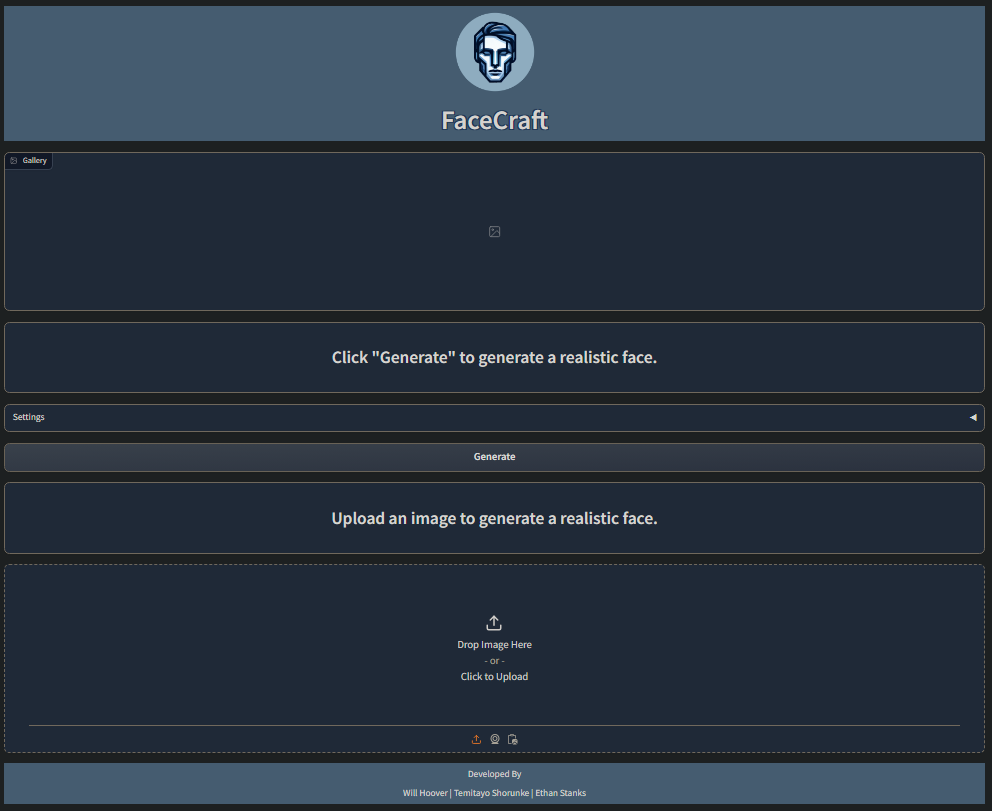
The changes made in our design document include a new logo and name, where the back-end and front-end will be hosted, and prompt rules. We decided that the front-end will no longer use the React framework. We found out that HuggingFace allows static website hosting and can easily access hosted models. The new framework used will be HTML, as it's a lot easier to deploy on HuggingFace.
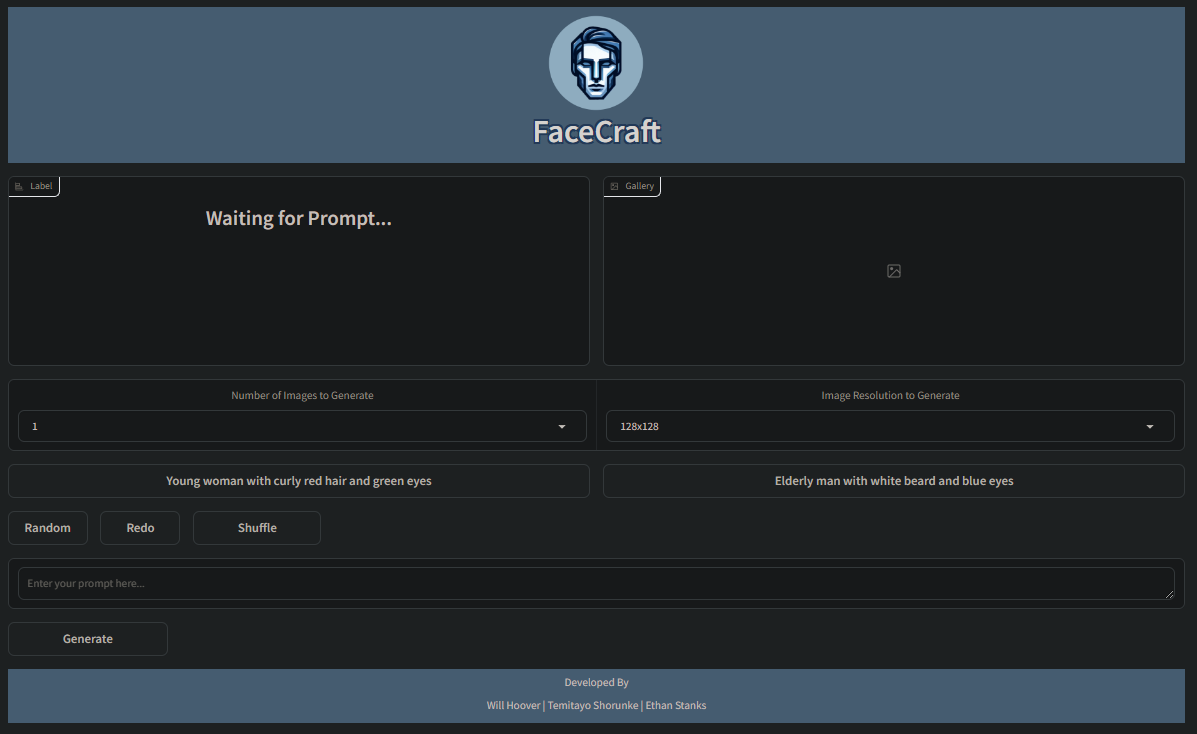
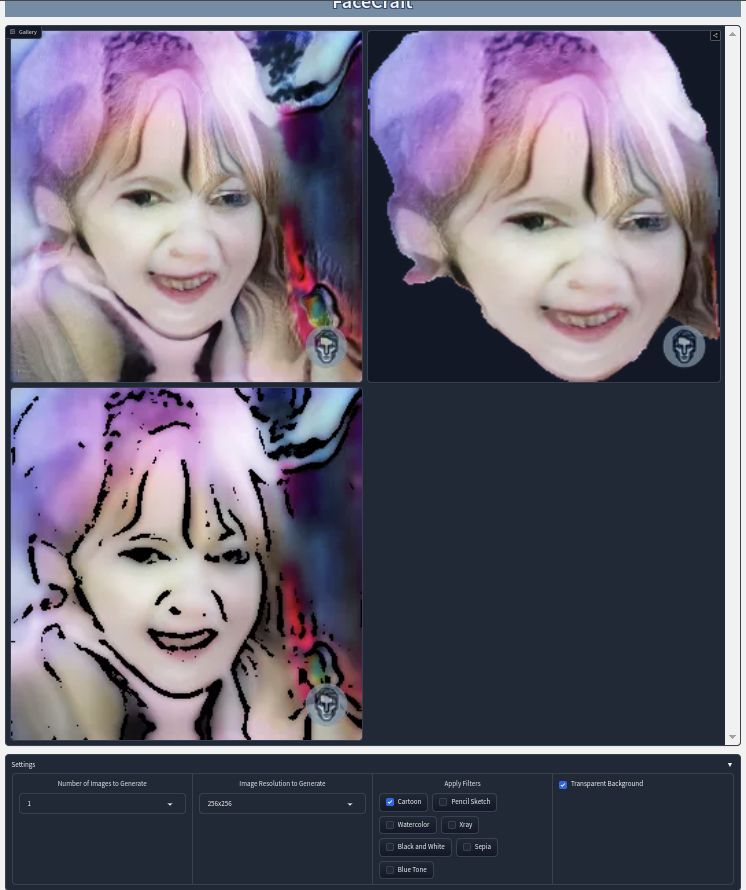
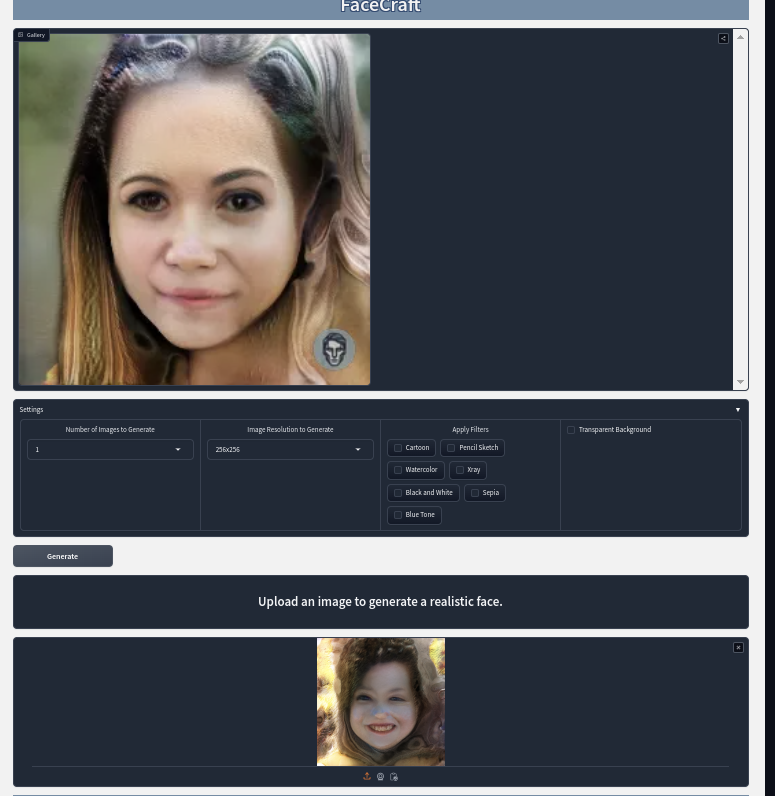
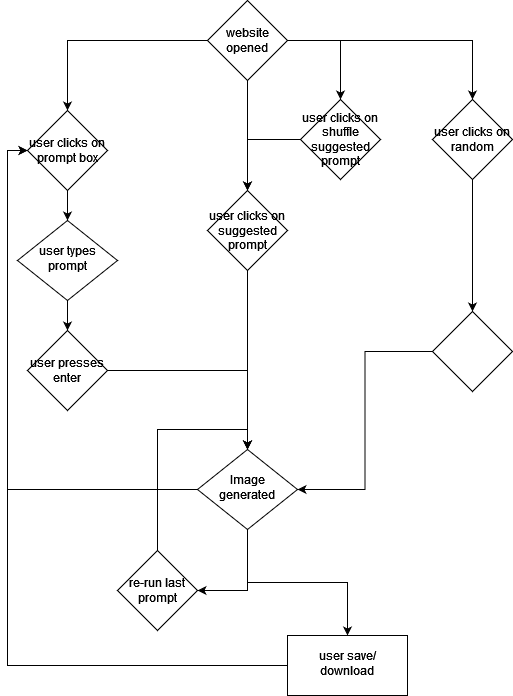
The first draft for the wireframe was created using Figma. I created it following the user flow the team had created in the design document. It will serve as a reference for when I start developing the front-end in month two. Below this post, you can see how it looks!
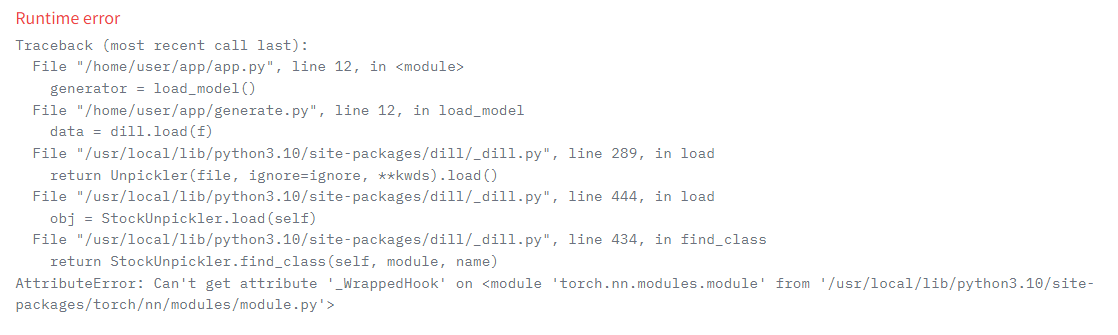
The Jira board has a total of 33 To-Dos across different To-Do categories: Dataset, NLP, GANS, Front-End, and Back-End. The team and I went through and added descriptions to each to-do as a measurable assessment that answers, "How do we know this task is complete?" The front-end and back-end to-dos have a lot of features under them, but I feel very confident in getting them knocked out within the first month. I believe Temitayo is developing the NLP model from a pre-trained model, and Will is developing the GANs model from scratch. I'm mostly worried about the GANs model, as I have no experience working with one, so I will try to help Will out when needed.
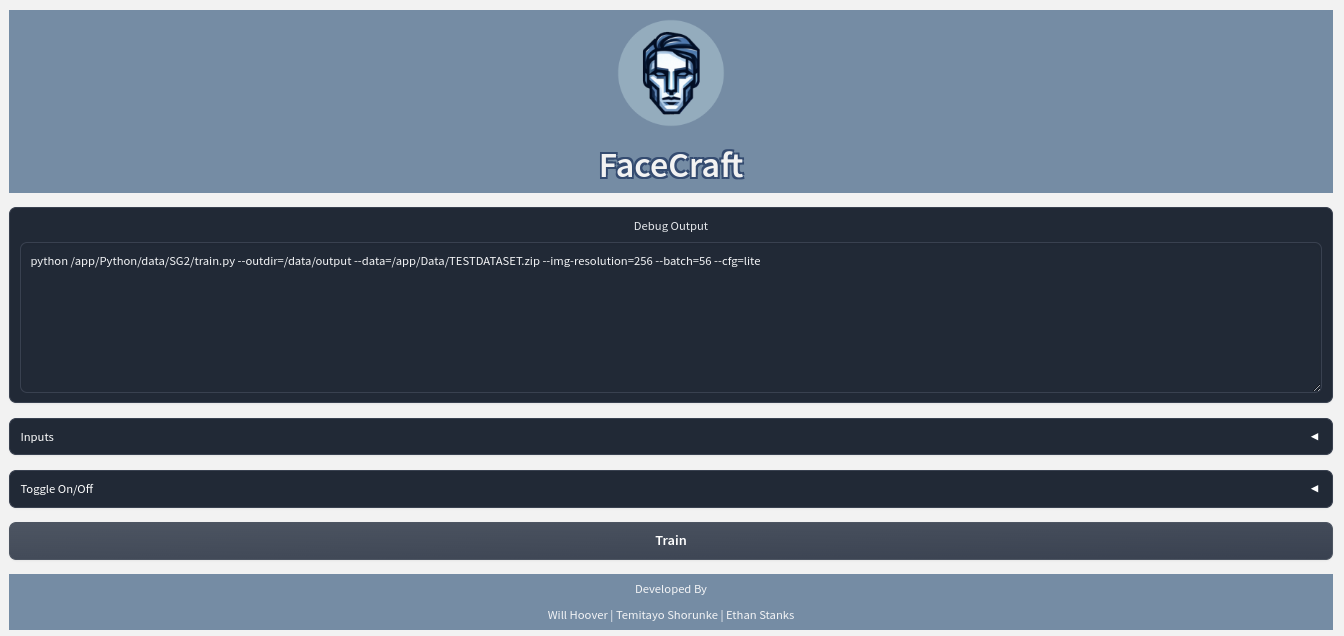
Aside from team development this week, I did more research on what I'll be doing. I messed around with CSS to get a better understanding of how styling HTML elements works. My practice was actually this website. I completely overhauled all the CSS on it, making it go from a basic-looking HTML website to a professional design. Since I know I'll be doing front-end on huggingface, I created an organization for the team and made a private interface space. The project's interface just has our new logo and a greeting for the team until I start the front-end development. Lastly, I started a LinkedIn Learning course on GAN models. I haven't finished it yet, but it utilizes Google Colab for model development.
One more week to go!
HuggingFace Research
Word Count: 466
This was the last week for project planning! Tomorrow starts my one-week spring break, then it's onto the first month of development.
Not much was done this week, but some productive tasks were completed. First, I got refreshed and learned more about sprint planning and SCRUM. During production months, the team and I will be completing one-week sprints in agile development. The final wireframe was due, but last week we already added the final touches, so nothing needed to change. At the start of the week, we met with Chad Gibson, our instructor, to go over our Jira board and the game plan for our project. I didn't have anything else to do for the week, so I thought I'd learn more about HuggingFace because that's what I'll be working on right away. My goal was to get a basic model hosted on HuggingFace and then make a basic HTML front-end for it on HuggingFace as well.
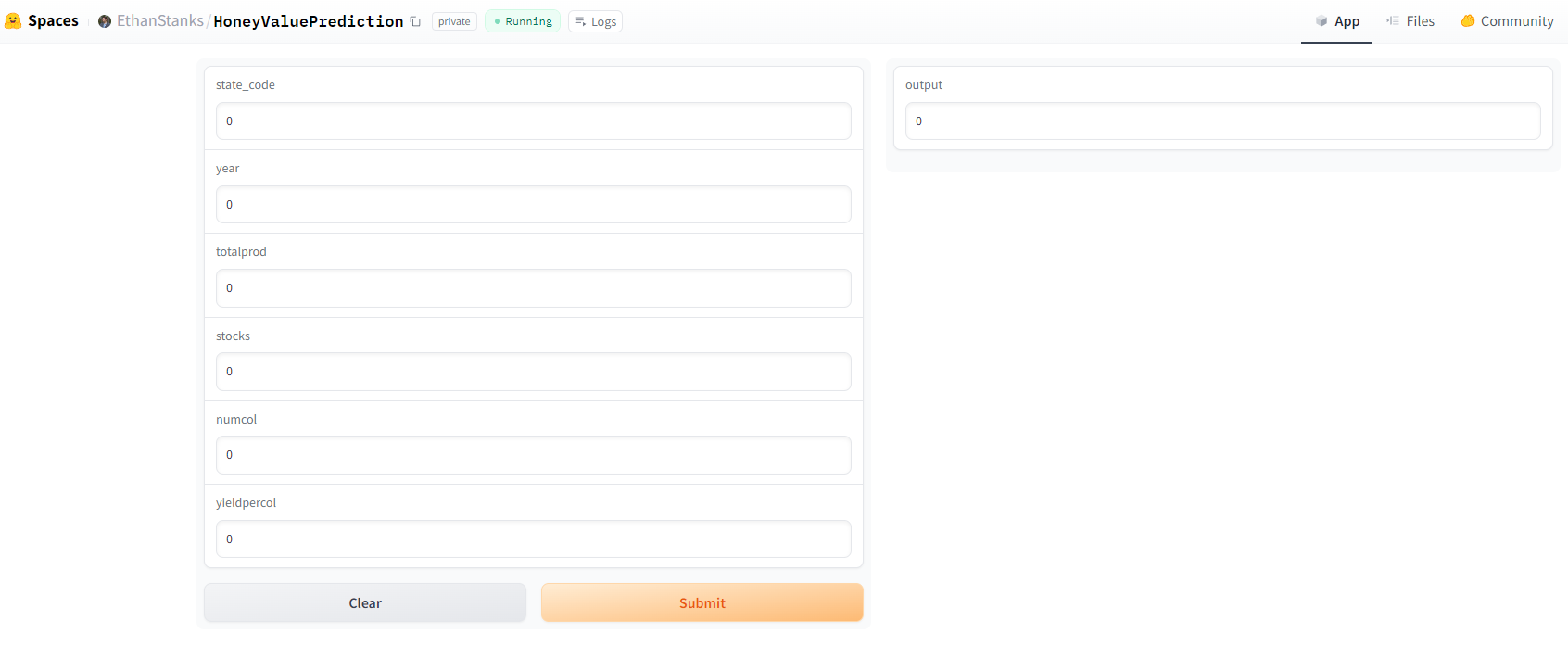
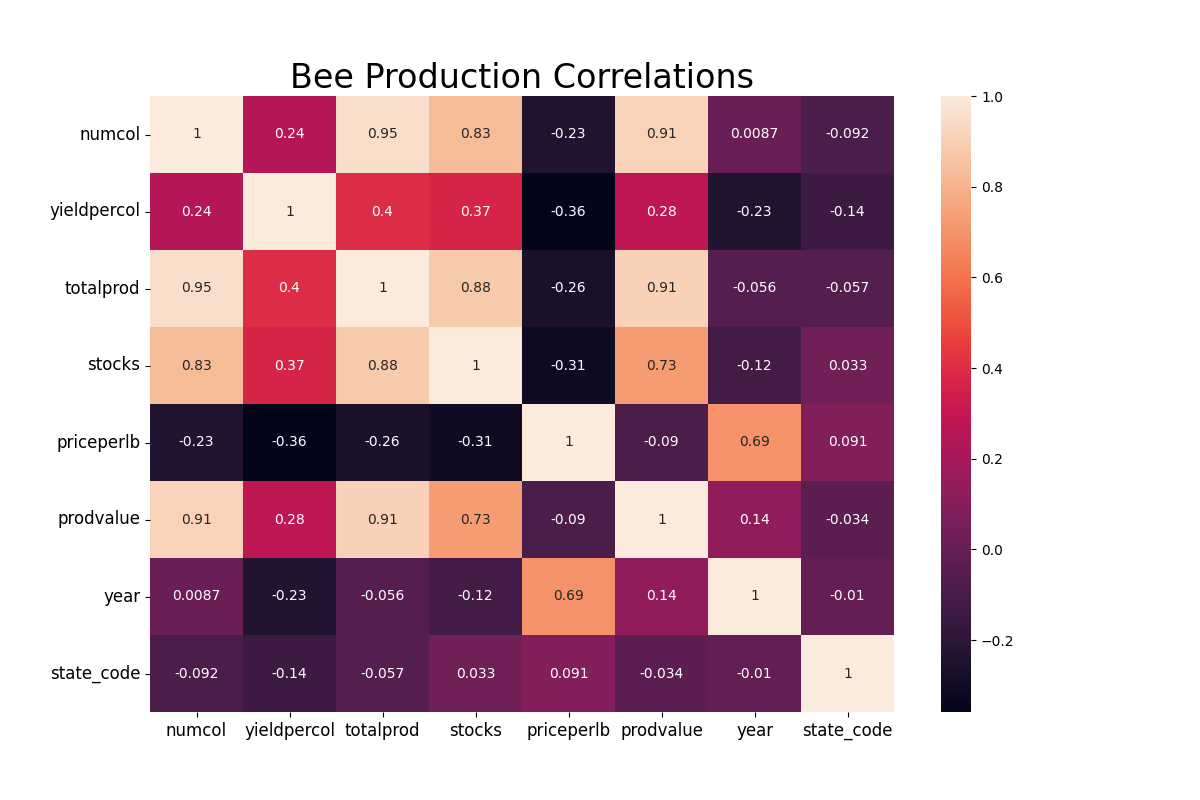
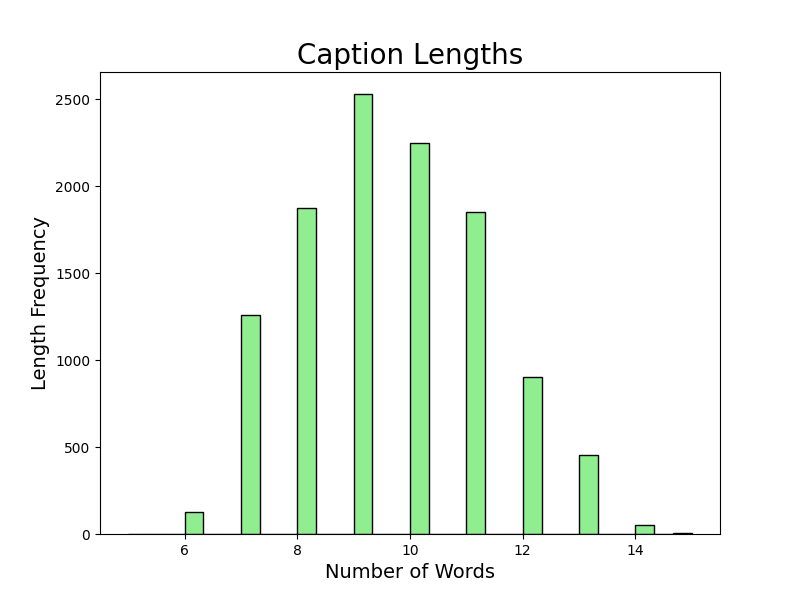
I found a free dataset on honey production in the USA from 1998 to 2012. I created some graphs for exploratory data analysis to see how well the data is and if there are any correlations I could use. My model is a basic KNeighborsRegressor from scikit-learn that predicts the honey's production value. It predicts this by learning these inputs: state, number of colonies, yield per colony, total production, stocks held by producers, and the year. The model, without any tweaking, performs at 82%, which is fine for the purpose it will serve.
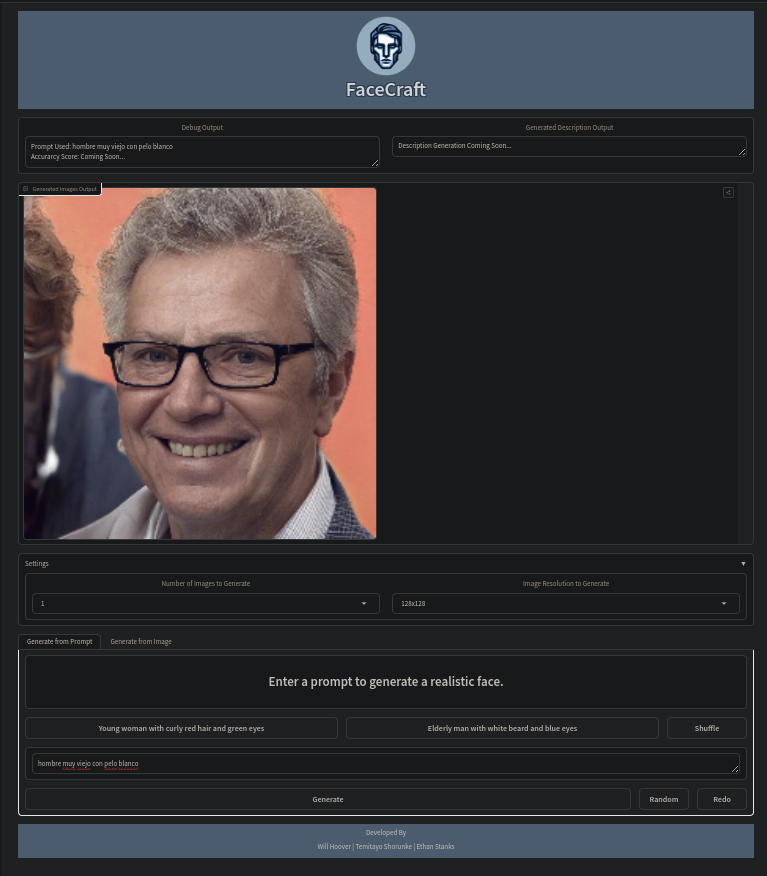
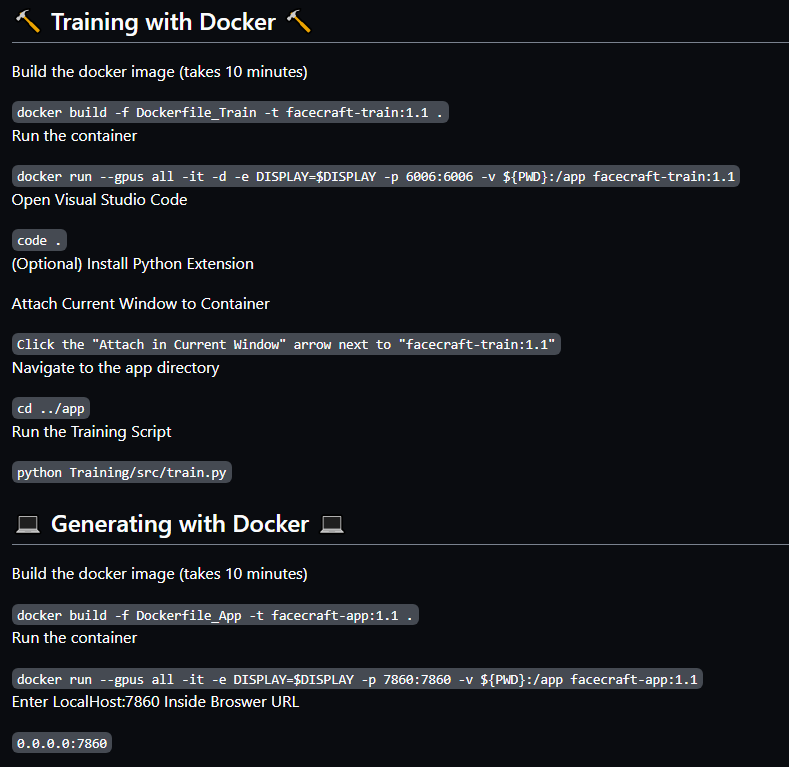
Next for HuggingFace, they have three ways to upload data to their platform. Models, which is like a git repo for AI models. Datasets, where you can share datasets you have gathered. Spaces, where you can create interactive spaces for your projects. My first hypothesis was to upload my model under their model section, then create a space as the front end and connect the two. After creating a basic HTML front-end with javascript to fetch and send data to the model, I ran into some issues. HuggingFace's API endpoint for models typically works for transformers, but I have a custom-made model, so I would need to create a custom API wrapper.
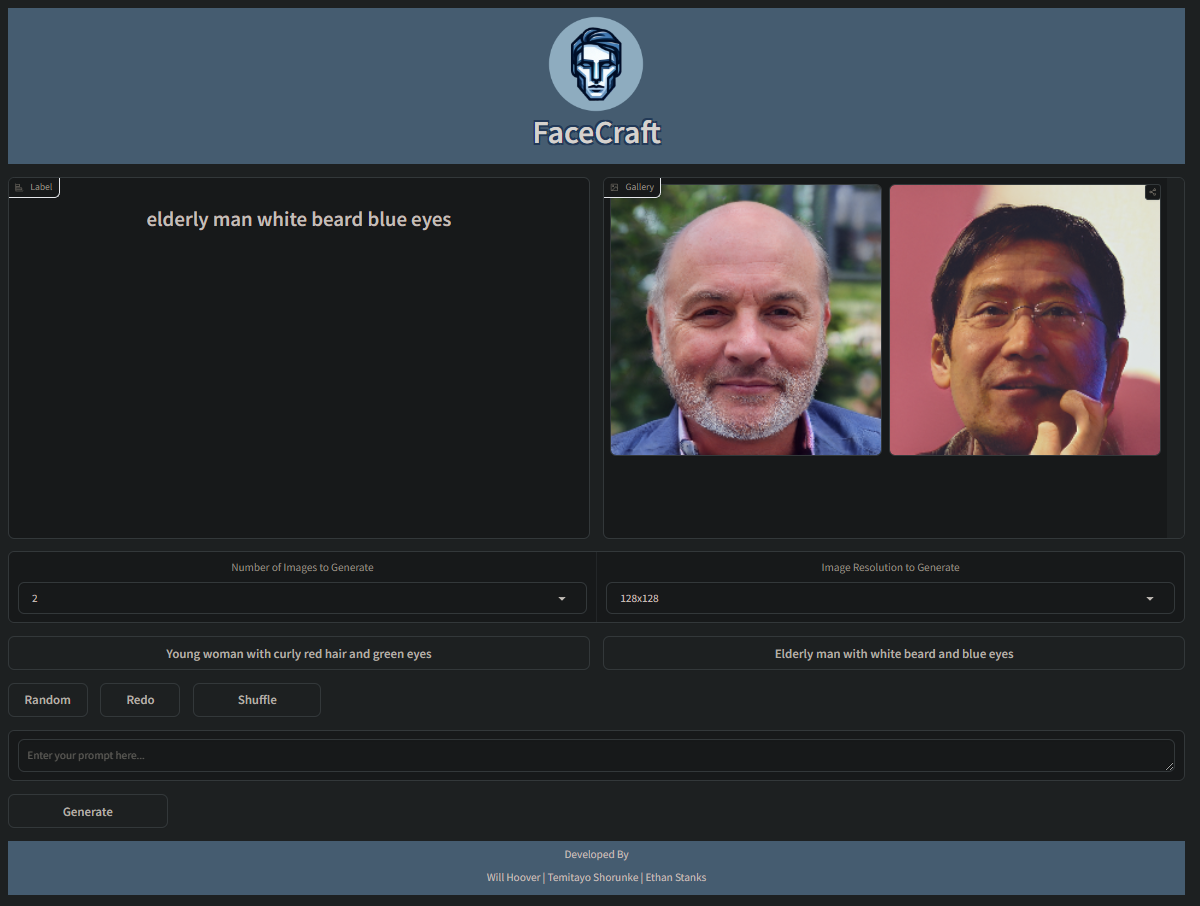
A workaround I found for the problem is to have the model and front-end all under one space. The space uses Gradio, an interactive front-end Python library that can easily load the model from the local library and call predictions. The application is up and running, and I can easily make predictions on my model in the cloud, which was the goal. Sadly, I didn't get this to work with HTML. Over spring break, I plan on researching more about custom wrappers for an HTML front-end!
Below you can see the correlation plot for the dataset and the basic interactive web-app hosted on HuggingFace.